

MS Clarity를 사용하는 중 데이터 내보내기라는 보았습니다. 대체 무슨 데이터를 내보낸다는 것일까... 라는 호기심이 생겨 한번 뽑아보기로 하였습니다. 우선 해당 메뉴에서 API 토큰을 생성받습니다.
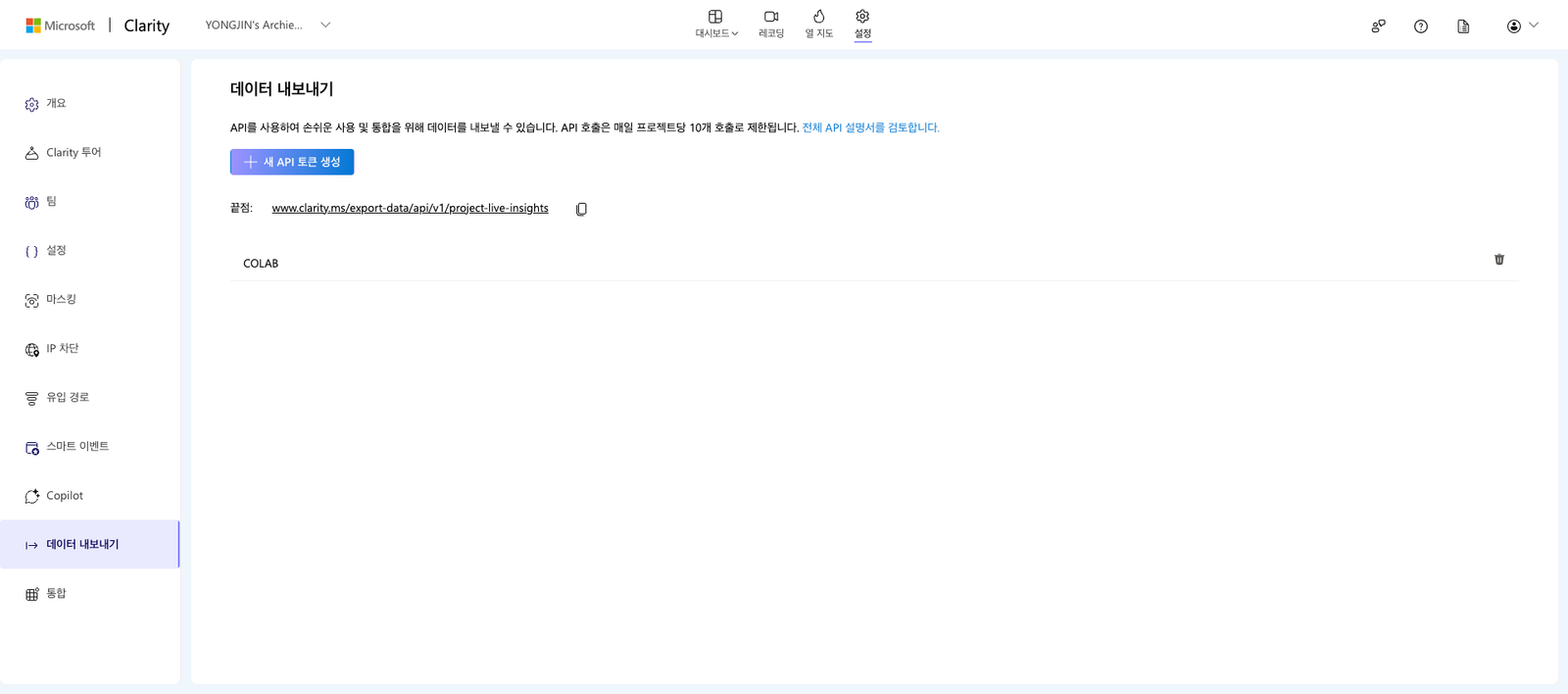
토큰을 받고나면, 어떻게 데이터를 뽑아야하나? 라는 문제가 생기죠. 우선 파이썬을 사용한다고 하면 현재 사용하는 컴퓨터에 파이썬이 깔려 있어야 파이썬으로 짠 코드를 실행할 수 있죠. 그렇지만 파이썬 깔기 귀찮죠? 그럼 Google Colab을 사용해봅시다.
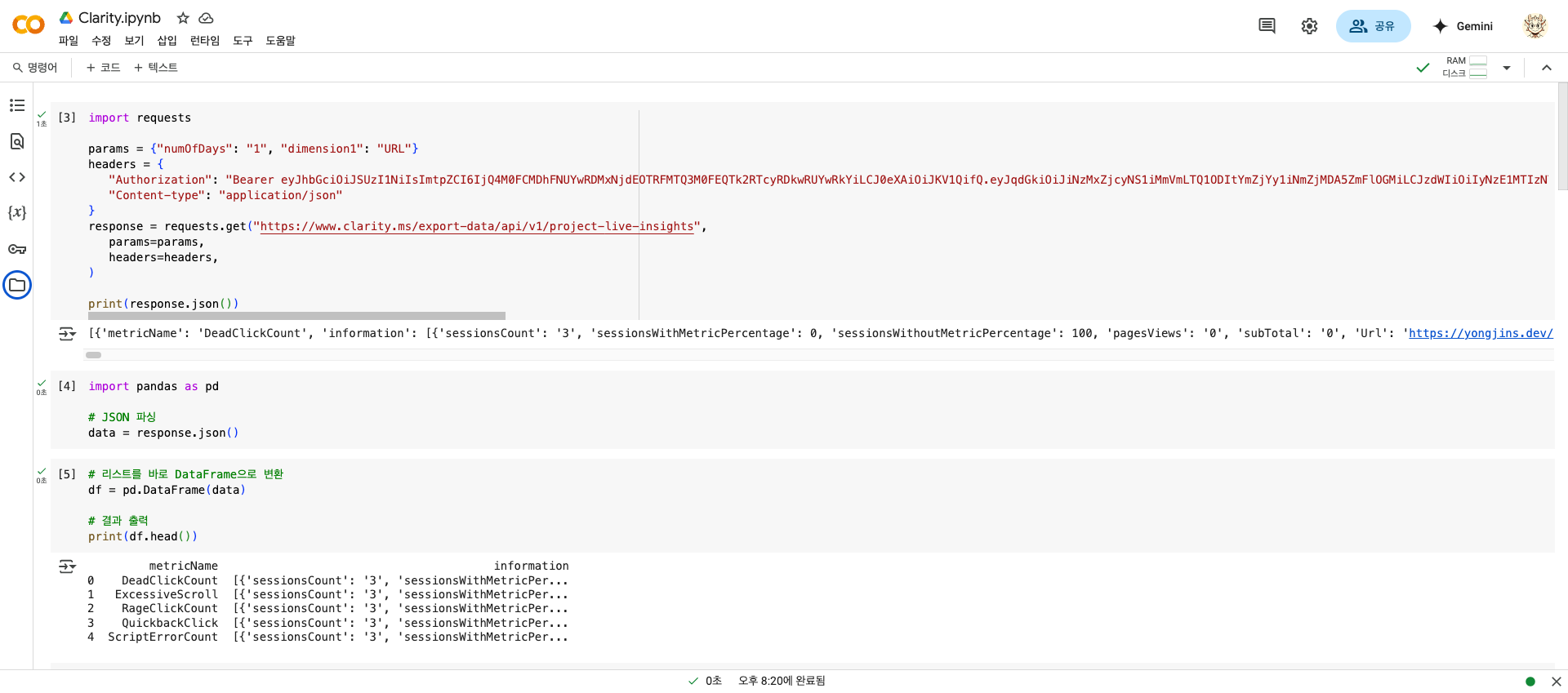
5년 전만 하더라도 파이썬을 모르면 사용하지 못하는 부분이겠지만, 이젠 우리에게 ChatGPT가 있죠. 그리고 클라리티에서는 최초에 데이터를 뽑을 수 있는 파이썬 코드도 알려줍니다. 다음과 같이 말이죠.
import requests
params = {"numOfDays": "1", "dimension1": "URL"}
headers = {
"Authorization": "Bearer API_TOKEN",
"Content-type": "application/json"
}
response = requests.get("https://www.clarity.ms/export-data/api/v1/project-live-insights",
params=params,
headers=headers,
)
print(response.json())아까 받은 토큰을 까먹지 않았다면 저 코드 안에 API_TOKEN에다가 토큰을 집어넣고 돌려버립시다. 그러면 다음과 같은 JSON을 토해냅니다. 꾸에에엑
[
{
"metricName": "DeadClickCount",
"information": [
{
"sessionsCount": "3",
"sessionsWithMetricPercentage": 0,
"sessionsWithoutMetricPercentage": 100,
"pagesViews": "0",
"subTotal": "0",
"Url": "https://yongjins.dev/"
},
{
"metricName": "ExcessiveScroll",
"information": [
{
"sessionsCount": "3",
"sessionsWithMetricPercentage": 0,
"sessionsWithoutMetricPercentage": 100,
"pagesViews": "0",
"subTotal": "0",
"Url": "https://yongjins.dev/"
},
}
]JSON은 컴퓨터가 서로 통신할 때 주고받는 파일 중 하나입니다. 그러니깐 컴퓨터와 컴퓨터가 서로 이해하기는 좋은 도구이지만 그걸 사람이 이해하기는 힘듭니다. 사람이 이해하기 쉽도록 해당 JSON을 ChatGPT에게 정리해달라고 하면 됩니다. 보통은 Pandas를 통한 데이터프레임으로 변환하여 제공해줍니다.
import pandas as pd
# JSON 파싱
data = response.json()
# 각 metric의 정보를 리스트로 변환
rows = []
for metric in data:
metric_name = metric["metricName"]
for info in metric["information"]:
row = {
"metricName": metric_name,
"Url": info.get("Url", None),
}
# 나머지 키들 포함
for key, value in info.items():
if key != "Url":
row[key] = value
rows.append(row)
# DataFrame 생성
df = pd.DataFrame(rows)
# 표시
pd.set_option('display.max_columns', None)
print(df)
# CSV로 출력
df.to_csv("clarity_metrics.csv", index=False)이렇게 만들면 인간이 이해하기 편하도록 표 형태로 만들어줍니다. 좋죠? CSV 파일은 엑셀이나 구글 스프레드시트로 보면 편합니다.
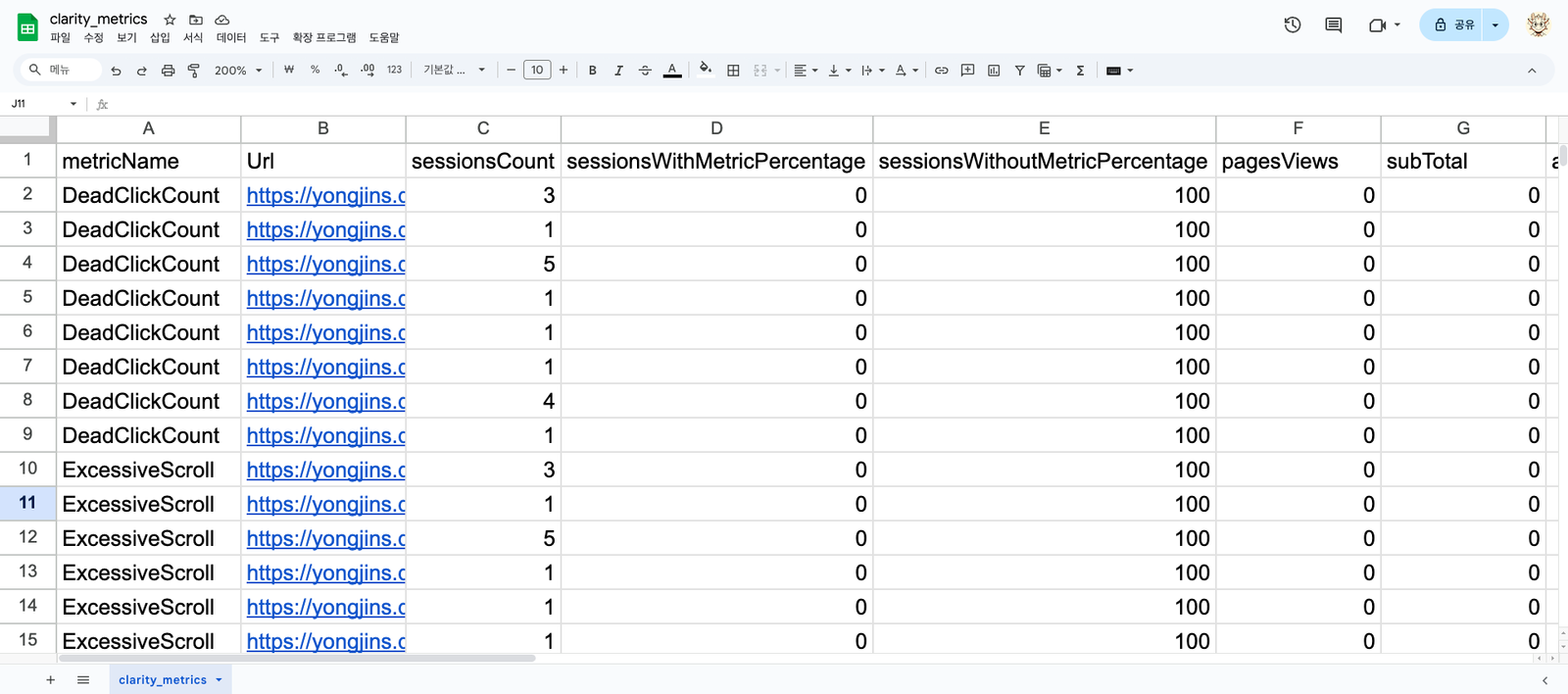
그렇지만 뭔가 보기 애매하네요. URL로 묶어서 보여달라고 한번 해볼까요?
# 피벗 테이블로 요약
pivot_df = df.pivot_table(
index='Url',
columns='metricName',
values='sessionsCount', # 또는 다른 값 예: 'totalTime'
aggfunc='sum' # 값이 여러 개면 합쳐서 보여줌
).fillna(0)
# 컬럼 정리 (보기가 더 깔끔해짐)
pivot_df.columns.name = None
pivot_df = pivot_df.reset_index()
print(pivot_df)
pivot_df.to_csv("clarity_url.csv", index=False)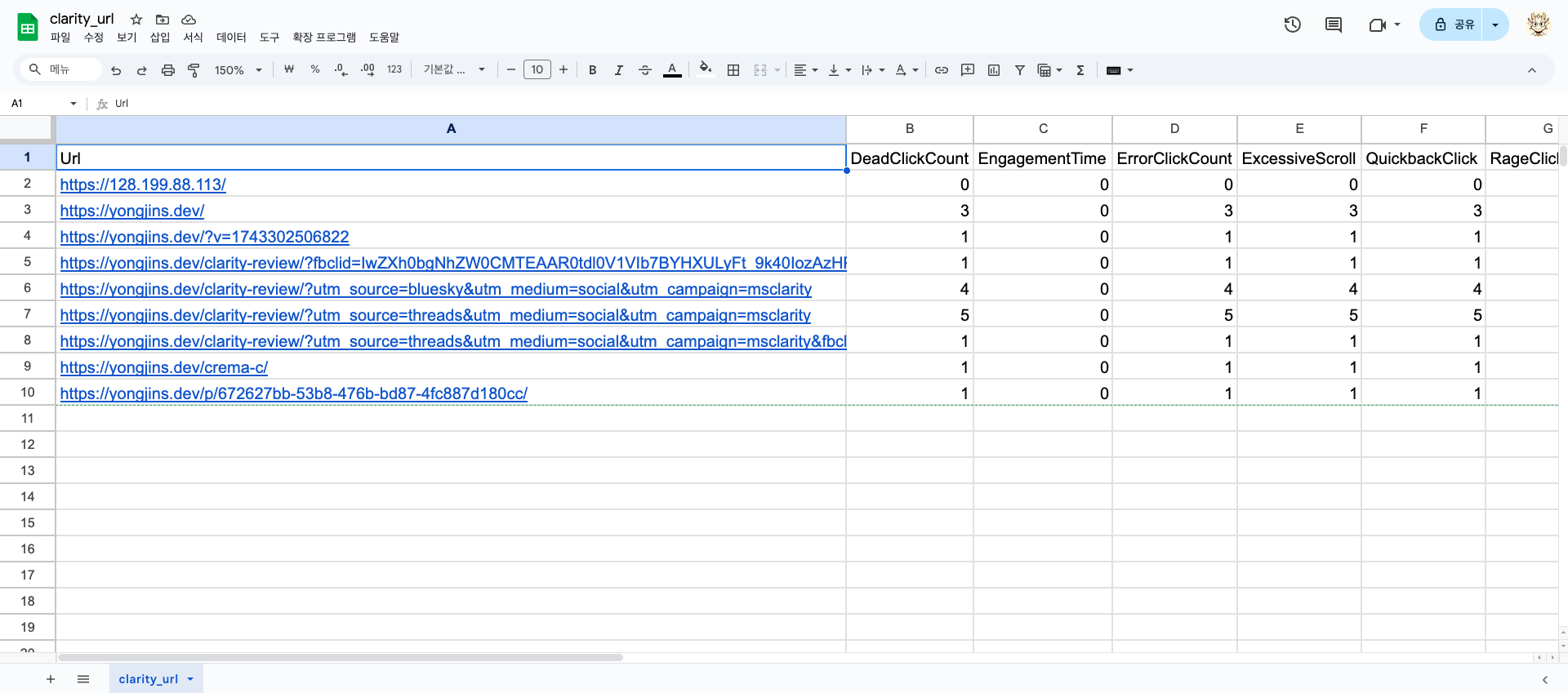
제 작고 귀여운 블로그로는 제한된 정보만 추출 가능하여 회사의 데이터를 뽑아내어 확인해본 결과 MS Clarity에서 주는 데이터는 다음과 같은 특징이 있었습니다.
- 해당 데이터는 사용자 동작에 대한 데이터를 제공해줍니다.
- 단, 데이터는 원시(raw) 데이터가 아닌 클라리티에서 정리한 값입니다.
- 클라리티에서 API call 한 번 당 3개의 차원만 가능하며, 메트릭을 조절할 수는 없습니다.
- 한 번에 뽑을 수 있는 데이터량은 1,000행으로 제한됩니다. 하루에 10번 사용 가능합니다.
아무래도 클라리티에서 자체적인 요약을 거친 값이기 때문에 해당 값을 통해서 무언가를 더 분석하는 것은 어려워보이는 게 현재의 제 생각입니다. 데이터 추출이 1000행으로 제한되는 것과 메트릭을 조절할 수 없는 것도 아쉬운 일입니다. 데이터가 많을 경우 내가 보고싶은 메트릭은 뽑히지 않는 경우도 있더군요.
저러한 제한으로 클래리티에서 데이터를 뽑아서 더 다른 분석을 해보는 것은 어려운 일 같습니다. 아쉽지만 2025년 3월 30일 현 시점에서는 클래리티는 웹에서 대시보드와 히트맵, 확장 익스텐션만 사용하는 것이 더 좋을 거 같습니다.










